

Use It or Lose It? Hallucinations in Chatbot Summaries: Understanding LLMs
Through my journey through the world of chatbots and language models, one of the most requested LLM features from business owners is for it to have the ability to summarize information accurately and concisely. However, one of the biggest concerns is about the potential for hallucinations in chatbot-generated summaries. In this blog post, I will explore the concept of hallucinations in chatbot summaries, specifically focusing on Large Language Models (LLMs). Additionally, I will offer some words of advice for LLM use and selection.
Understanding LLMs: LLMs, or Large Language Models, are powerful AI models that have been trained on vast amounts of text data. These models have the ability to generate human-like text and are often used in chatbot applications. LLMs can process and understand natural language, making them ideal for tasks such as summarization.
Understanding Hallucinations: In the context of chatbot summaries, hallucinations refer to unusual outputs produced by AI models when they misinterpret data. AI models, such as chatbots, are trained on a large amount of data and make creative connections based on what they have learned. Sometimes, these connections can be "creative" and result in outputs that may not accurately reflect the intended meaning or context. Hallucinations can occur when the AI model generates responses that are unexpected or nonsensical. While LLMs can generate fluent and convincing text, they lack true understanding of the meaning or broader context of the sentences they generate. Therefore, it is important to verify and fact-check the outputs and not blindly trust them without human review.
Let's take a closer look at some popular LLMs:
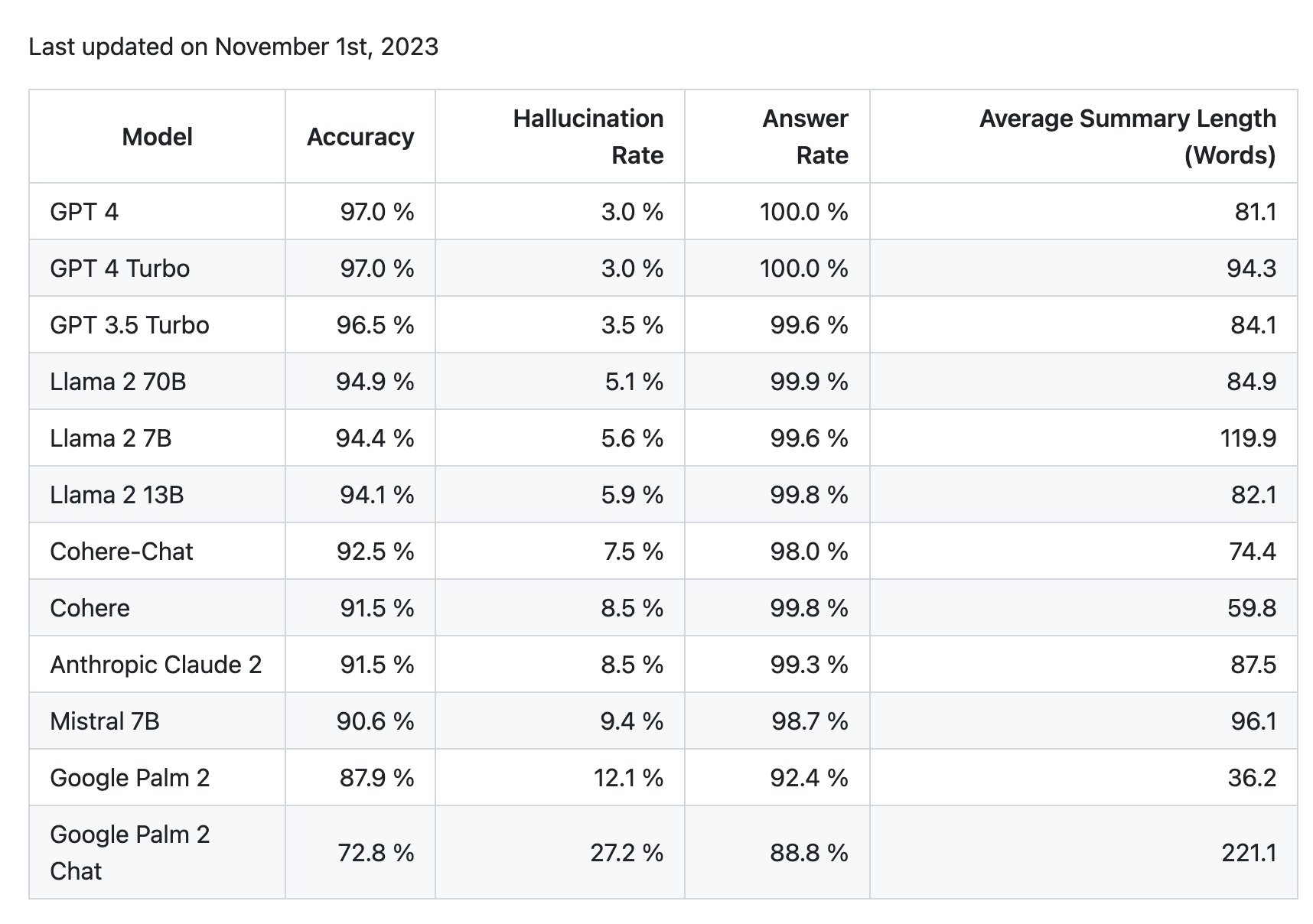
GPT-4: Renowned for its comprehensive understanding and response accuracy, setting a high standard in AI language models.
GPT-4 Turbo: Offers a balance between the sophisticated capabilities of GPT-4 and enhanced response speed.
GPT-3.5 Turbo: A slightly less advanced but still highly capable version, maintaining good accuracy with efficient response times.
Llama 2 70B: Stands out for its unique approach to language understanding, although with a somewhat higher tendency for errors.
Llama 2 7B: A more compact version in the Llama series, balancing accuracy with a slightly elevated hallucination rate.
Llama 2 13B: Offers a middle ground in the Llama series, balancing size and performance.
Cohere-Chat: Notable for its high accuracy, making it a competitive choice in the AI language model space.
Cohere: Provides solid performance, especially in summarization, suitable for various applications.
Anthropic Claude 2: Known for its effective summarization and accurate responses, albeit with slightly lower performance.
Mistral 7B: Offers good accuracy and summarization, tailored for specific use cases requiring these strengths.
Google Palm: Integrates Google's advanced AI technology, focusing on a wide range of applications with robust performance.
Google Palm 2 Chat: Enhances the Google Palm technology with a specific emphasis on conversational AI, offering nuanced and accurate interactions.
Reasons to Continue Using LLMs:
Accuracy: LLMs have shown high accuracy in summarizing short documents, making them valuable tools for information retrieval and knowledge extraction.
Language Understanding: LLMs have a solid grasp of language and can generate coherent and contextually relevant summaries.
Speed and Efficiency: LLMs can process and generate summaries quickly, enabling faster response times in chatbot applications.
Continuous Improvement: LLMs are constantly evolving and improving, with new models and updates being released regularly. This ensures that the performance and accuracy of LLMs continue to improve over time.
Words of Advice for LLM Use and Selection:
Understand Your Use Case: Clearly define your requirements and objectives when selecting an LLM. Consider factors such as accuracy, response time, and content restrictions.
Evaluate Performance Metrics: Look beyond hallucination rates and consider other performance metrics such as accuracy, summarization quality, and response time.
Test and Compare: Conduct thorough testing and comparison of different LLMs to determine which one best suits your specific needs. Consider using benchmark datasets and real-world scenarios to evaluate performance.
Stay Updated: Keep track of the latest advancements in LLM technology and regularly update your models to benefit from improved performance and accuracy.
Use It or Lose It? Use It!
Use It! Hallucinations in chatbot summaries can be a concern, but with the right understanding and selection of LLMs, these issues can be mitigated. By considering the pros and cons of different LLMs, understanding their capabilities, and following best practices, chatbot users and developers can harness the power of LLMs to provide accurate and reliable summaries in their applications.
Want More?
Discuss modernizing your technology infrastructure.
Learn more about our artificial intelligence consulting services.
Learn more about Opportunities 2 Serve through our chatbot, Kody.
Learn more about AI through our blog, “Use It or Lose It? AI-Driven Productivity Tools.”
Do you think you’re ready to adopt AI into your business practices, but you’re unsure where to start? Complete a brief AI Readiness Assessment.